Technology
EarthDefine uses different machine learning approaches based on the classification context to extract features of interest from geospatial data. For some of our products we build deep neural networks using millions of training samples that deliver significantly better performance in comparison to traditional machine learning methods.
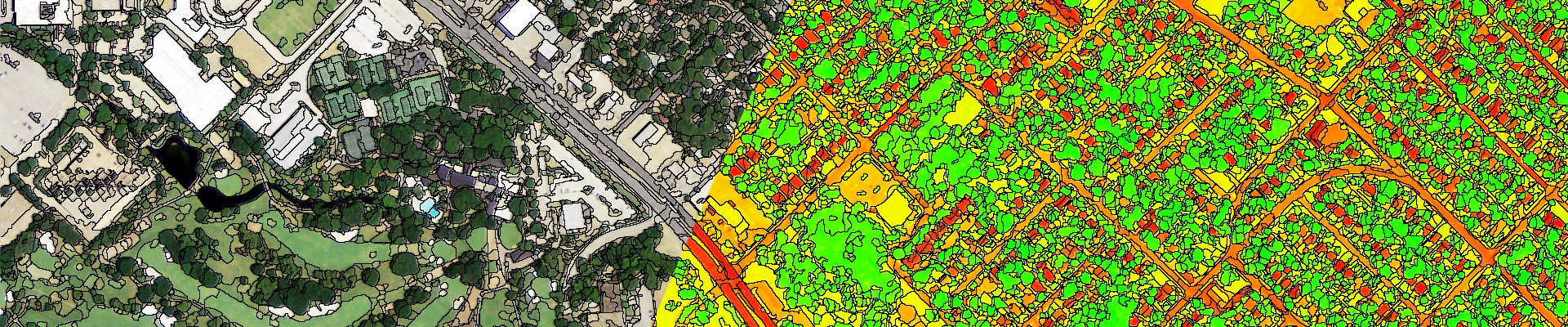
We also employ a Geographic Object-Based Image Analysis (GEOBIA) processing framework to create our land cover products using data from multiple data sources. The core units of analysis under a GEOBIA approach are image-objects instead of pixels. The GEOBIA paradigm allows the creation of higher accuracy and relatively noise free land cover products compared to pixel based methods.
Historically, development of high-resolution land cover products (1m or better) using GEOBIA approaches has been limited to projects over small geographical extents like small watersheds, cities or counties. Hardware and software limitations have often made high-resolution GEOBIA over large areal extents, a long and prohibitively expensive process. EarthDefine has addressed these challenges by developing a proprietary high throughput GEOBIA platform that enables massively scaled image segmentation and object based classification on large computing clusters. This enables us to develop cost effective solutions for high-resolution land cover mapping over large geographical areas.
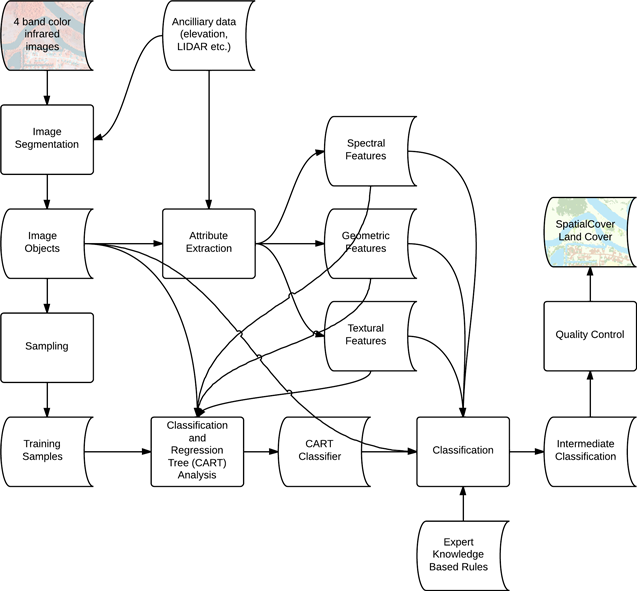
The source images are partitioned into meaningful image-objects that represent features on the earth's surface. This is done by grouping spatially contiguous pixels using automated image segmentation algorithms. These objects enable the quantification of spectral, geometric, textural and contextual properties on actual ground features of interest that are comprised of one or more objects. Object properties and adjacency/contiguity relationships between objects and ancillary data sources on transportation, terrain, demography, hydrology etc., are quantified and stored for use in a scalable processing workflow. The table below lists some data layers that provide useful variables for the classification workflow:
| Image and Derivatives Layers | Haralick Texture Layers | Ancillary Layers |
|---|---|---|
|
|
|
Statistical properties like the mean, standard deviation, variance, median, kurtosis, skewness, etc., are computed for the source data layers to create hundreds of potentially useful variables that describe each image object. In addition, geometric properties like object size, centroid, axis lengths, elongation, eccentricity, orientation, etc. offer additional metrics that can help differentiate certain classes.
We employ Classification and Regression Trees (CART) algorithms to develop classifiers using the different spectral and geometric properties of objects. CART provides a robust data mining approach for classifying objects and identifying the object attributes that add the most information to the classification algorithm. The CART approach involves the development of binary decision trees from a large number of training samples for which the correct classification is known. CART classifiers are trained and applied using object level attributes along with additional rules based on expert knowledge in an integrated classification workflow, to create our data products.
Land Cover Derivation Workflow Example
Let's Talk Data
Contact Us
8410 154th Avenue NE, Suite C-240
Redmond, WA 98052
Phone: 1.800.579.5916
Email: info@earthdefine.com
2025 © All Rights Reserved.